Appearance
🚀 Mastering Dynamic Resource Orchestration in Kubernetes
The cloud is vast, but fear not, fellow traveler! In the realm of cloud-native applications, maintaining optimal performance and cost-efficiency requires a keen understanding of dynamic resource orchestration. As workloads fluctuate, the ability to automatically adjust computing resources is not just a luxury, but a necessity. Today, we're diving deep into Kubernetes' powerful autoscaling mechanisms: Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA), and Cluster Autoscaler (CA). These tools collectively enable true resource elasticity and seamless dynamic resource allocation.
What is Dynamic Resource Orchestration? ♾️
At its core, dynamic resource orchestration refers to the automated, intelligent management and allocation of computing resources based on real-time demand. Imagine your applications as living entities, needing more or less CPU, memory, or even more instances of themselves, depending on the current load. Dynamic orchestration ensures these needs are met instantly, preventing performance bottlenecks and optimizing infrastructure costs.
In Kubernetes, this translates to systems that can:
- Scale applications horizontally: Adding or removing Pod replicas.
- Scale applications vertically: Adjusting the CPU and memory allocated to individual Pods.
- Scale infrastructure: Adding or removing worker nodes in the cluster.
Let's explore how Kubernetes empowers us to achieve this.
📈 Horizontal Pod Autoscaler (HPA): Scaling Out When Demand Soars
The Horizontal Pod Autoscaler (HPA) automatically adjusts the number of Pod replicas in a Deployment, ReplicaSet, or StatefulSet based on observed CPU utilization, memory utilization, or custom metrics. This is your go-to for scaling out when traffic spikes.
How it Works: HPA continuously monitors the specified metrics. When the average metric value across all Pods exceeds a target threshold, HPA increases the number of Pods. Conversely, if the metrics drop below the threshold, HPA reduces the Pod count.
HPA in Action: A CPU-Bound Example
Let's say you have a web application that experiences varying traffic. You want to ensure it can handle load spikes without manual intervention.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
app: php-apache
replicas: 1
template:
metadata:
labels:
app: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
resources:
limits:
cpu: 500m
requests:
cpu: 200m
ports:
- containerPort: 80
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50In this example:
- We define a
php-apacheDeployment with initial1replica. - The
HorizontalPodAutoscalerphp-apache-hpatargets this Deployment. - It's configured to maintain an average CPU utilization of
50%. - The number of Pods will scale between
1and10.
If the average CPU utilization of the php-apache Pods goes above 50%, HPA will add more Pods. If it drops significantly, Pods will be removed.
🔽 Vertical Pod Autoscaler (VPA): Optimizing Individual Pod Resources
While HPA handles horizontal scaling, the Vertical Pod Autoscaler (VPA) is all about optimizing resource allocation for individual Pods. VPA automatically adjusts the CPU and memory requests and limits for containers in your Pods. This is crucial for applications that are resource-hungry or have fluctuating per-instance needs.
How it Works: VPA observes the actual resource usage of Pods over time. Based on this historical data and current recommendations, it can update the resource requests and limits of running Pods (though typically it works by evicting and recreating Pods with updated configurations). This helps prevent resource waste (over-provisioning) and performance issues (under-provisioning).
VPA in Action: Ensuring Right-Sizing
Consider an application where you're unsure of the optimal CPU and memory requests. VPA can help discover these values.
yaml
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto" # Or "Off" to just get recommendations
resourcePolicy:
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 50Mi
maxAllowed:
cpu: 2
memory: 8GiHere, my-app-vpa will target the my-app Deployment. With updateMode: "Auto", VPA will automatically adjust the resource requests/limits for my-app Pods. You can also set updateMode: "Off" to only get recommendations without VPA applying them.
🌐 Cluster Autoscaler (CA): Scaling Your Infrastructure
The Cluster Autoscaler (CA) works at a higher level than HPA and VPA. It automatically adjusts the number of worker nodes in your Kubernetes cluster. When Pods cannot be scheduled due to insufficient resources, CA adds new nodes. When nodes are underutilized and their Pods can be compacted onto other existing nodes, CA removes them. This ensures your cluster always has just enough capacity to run your workloads, contributing significantly to dynamic resource orchestration at the infrastructure layer.
How it Works: CA monitors pending Pods (those that couldn't be scheduled) and node utilization.
- If Pods are pending because there are no available nodes with enough resources, CA scales up the cluster by adding new nodes.
- If nodes are underutilized for an extended period, and all Pods on them can be gracefully moved to other nodes, CA scales down by removing those nodes.
Visualizing Kubernetes Autoscaling 🖼️
This diagram illustrates how HPA, VPA, and Cluster Autoscaler interact to provide comprehensive dynamic resource orchestration:
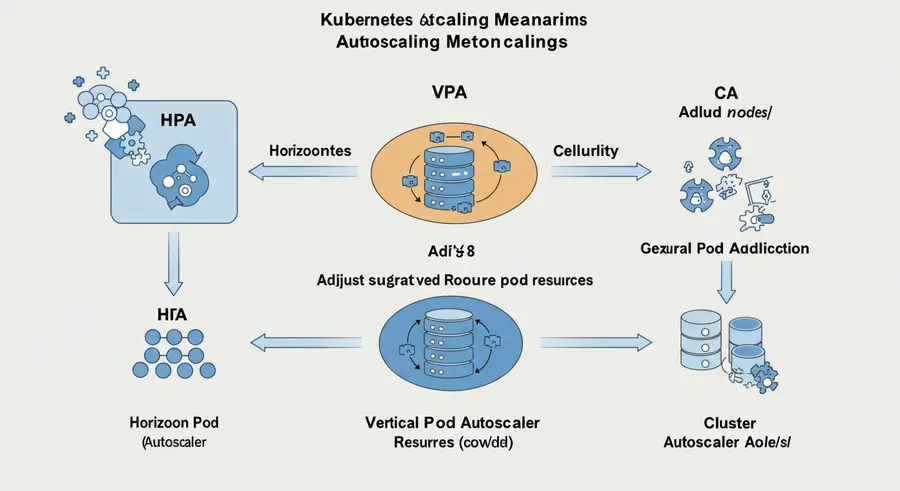
- HPA scales the number of Pods within existing nodes.
- VPA scales the resources (CPU/Memory) of individual Pods.
- Cluster Autoscaler scales the underlying infrastructure (nodes) to accommodate Pods.
Crafting an Optimal Resource Orchestration Strategy ☁️🚀
For a robust dynamic resource orchestration strategy, combine these autoscaling tools:
- Start with Resource Requests and Limits: This is foundational. Define realistic
requests(guaranteed resources) andlimits(hard caps) for all your containers. This helps the Kubernetes scheduler place Pods efficiently and provides baselines for VPA. - Implement HPA for Horizontal Scaling: Use HPA to handle fluctuating traffic and ensure your application remains responsive by adding or removing Pod replicas.
- Deploy VPA for Vertical Optimization: VPA complements HPA by fine-tuning the resource allocations for individual Pods, preventing over-provisioning and ensuring optimal performance within the Pod itself.
- Integrate Cluster Autoscaler for Infrastructure Elasticity: CA ensures that your cluster infrastructure can dynamically grow or shrink to match the demands of your HPA and VPA decisions. If HPA scales up and there aren't enough nodes, CA will provision new ones.
- Monitor and Observe: "Observability is key." Continuously monitor your application performance, resource usage, and autoscaling events. Tools like Prometheus, Grafana, and your cloud provider's monitoring solutions are essential for understanding how your autoscaling strategy is performing and identifying areas for improvement.
Conclusion: Automate Your Way to Enlightenment 📈
Dynamic resource orchestration in Kubernetes, through the intelligent combination of HPA, VPA, and Cluster Autoscaler, is a cornerstone of building resilient, cost-effective, and highly performant cloud-native applications. By automating these critical scaling decisions, you can reduce manual overhead, improve system reliability, and ensure your applications gracefully adapt to changing demands.
"Code your infrastructure." By treating your scaling policies as code, you gain consistency, repeatability, and version control over your resource management. Embrace these powerful tools, architect for scale, and let Kubernetes handle the complex dance of resource allocation.
References and Further Reading:
- Kubernetes Official Documentation on Autoscaling: https://kubernetes.io/docs/concepts/workloads/autoscaling/
- Horizontal Pod Autoscaler: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
- Vertical Pod Autoscaler: https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
- Cluster Autoscaler: https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler
- Lifting the Fog of Uncertainties: Dynamic Resource Orchestration for the Containerized Cloud: https://arxiv.org/abs/2309.16962